
HTTP/2 is big deal, at least for performance engineers. When HP LoadRunner version 12 mentioned SPDY support in the release notes, I started looking into it. I mentioned SPDY in passing in my article here.
Steve Gibson recently did a wonderful overview of HTTP/2 on the “Security Now” podcast. I highly recommend you listen to the last half of episode #495. I am including a lot reference links in this article and at the bottom of this article page to satisfy inquiring minds that will want to know more. I felt it was time the performance testing community start a discussion because this is something we’re going to really like.
SPDY
SPDY was the result of a research project by Google to see how HTTP version 1.1 might be improved. Google first introduced SPDY in 2009, and the protocol was integrated into Chrome, Internet Explorer, and Firefox. In 2012, work began on Hypertext Transfer Protocol 2 in response to SPDY’s improvements over HTTP 1.1 regarding performance and security.
SPDY version 2 was the basis for HTTP/2. Now the Internet Engineering Task Force’s HTTP Working Group finalized the specification on HTTP/2 and HPACK (a specification for compressing HTTP/2 headers). Google has already announced official support for HTTP/2 in Chrome version 40, removing SPDY support in 2016. Firefox 36 (released 2/24/15) now comes with full support for HTTP/2, and Microsoft has announced support for it in Windows 10 (it’s in the W10 preview). It’s worth a review of HTTP’s earlier versions and how it works to understand why things needed to be changed.
HTTP Version 1.0
HTTP (Hyper Text Transport Protocol). Yes, children – it was originally meant to be a text-based protocol (ok, maybe a couple of pictures). Once the web browser took off, it didn’t take long to realize there were limitations that needed to be dealt with. These days, web pages are full of graphics, script libraries, flash, calls to other web services, add-ons, and plug-ins that do all kinds of things.
HTTP Version 1.1
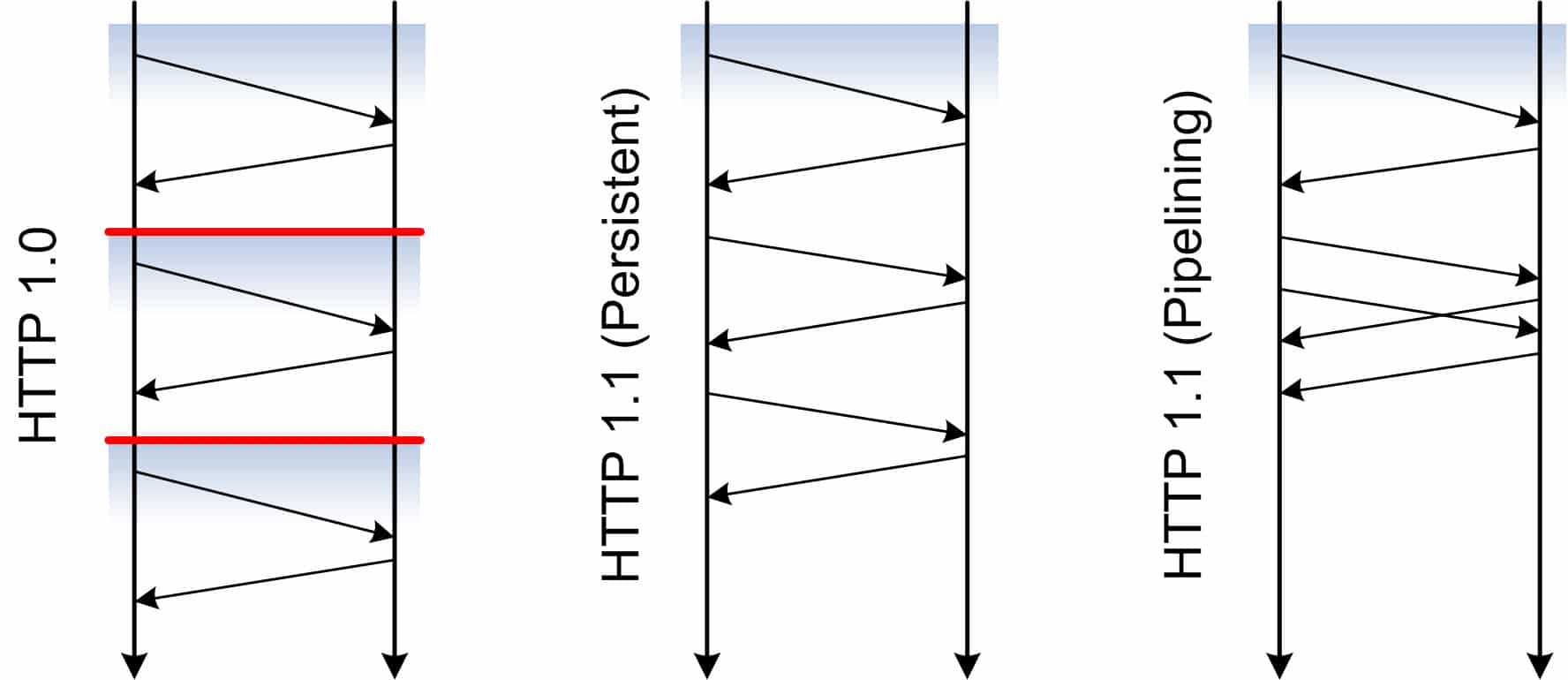
With the HTTP 1.1 revision, there were a couple of new features that attempted to deal with the limitations of version 1.0. Persistence (or “Keep Alive”) allowed multiple requests to use an existing TCP connection. However, it was still one request and one response at a time. Pipelining allowed for queries to be sent to the server even if you hadn’t received the previous response back. Unfortunately, it was hard to implement and did not provide much of a performance boost. The biggest issue (head-of-line blocking) was not effectively solved.
For 15 years, developers have been trying to make browsers do things they were not designed for originally. There are sites like YSlow that have a list of best practices to improve the performance of the front end user experience, but it’s still just working around the limitations of HTTP. As pages have become bigger and more complex, there is more pressure on browsers to handle the mess and make it appear fast to the user.
How HTTP 1.1 Works
A browser (the client) makes a request to a server for an HTML file. That text-based HTML file contains all of the descriptions for all of the other resources that will need to be requested by the client to render a full web page that includes graphics, CSS style sheets, scripts, etc… Once the browser has the HTML file, it parses it and makes all additional requests for the content it needs. Those resources may exist on the original server or other servers.
The browser needs all of this information to display the page correctly. In addition to the request for resources, there are also HTTP headers that are passed back and forth that contain more information like what browser version (User-Agent), Date/Time, Host name, sizes of request bodies, cookies, etc . HTTP headers can be useful to reduce some round trips by checking to see if there is local copy of something (like static images) in cache that can be used if it hasn’t expired. Cookies help maintain the session state so the server can remember the session conversation and put it into context. Remember HTML verses URL recording modes in LoadRunner?
In the early days, browsers would only open two connections per server. There could be more than two total if multiple servers were being connected to. If more than two per server connections were opened, it could overload a server. I can remember seeing the limit of connections defined in a web server configuration file, and running a load test to see what would happen when that number was breached. The web server would immediately stop serving pages, and it would be down. Eventually, servers got more powerful and browser vendors raised the number of simultaneous connections. When Firefox began to allow six connections, Microsoft responded with eight. The browser war was about making the client GUI appear faster to the user so it would the default. Behind the scenes, the browser was simply downloading resources using more connections. That is a band aid, not a solution. Multiple connections still share the same network bandwidth. To solve the problem, we need to deal with the root issue.
TCP: The Underlying Protocol
TCP sits at a lower level underneath HTTP and controls how fast packets can be moved. This is why knowing the OSI model is so important. TCP has four control mechanisms built in that help it deal with dynamic network conditions. You can read more about that here. One feature is called “Slow Start”. This is how TCP determines how fast it should be making requests. Too slow, and the client is not utilizing the connection efficiently. Too fast, and packets start dropping and the buffers in the routers start to overflow. TCP may have to slow down down because of some external bottleneck between the client and the server that is out of the clients control. Because TCP has guaranteed delivery, the client won’t know packets have dropped until the original requests are acknowledged. Once the client finds out, TCP adjusts. TCP will slowly increase the speed of requests until it senses packets are being dropped. This is how it determines the optimal pace.
When browsers open more than one connection, each individual connection goes through this slow start discovery process independently. When a site uses HTTPS, it further slows things down because each connection has to establish the TCP connection and the TLS security handshake independently. This puts additional load on the web server. Hardware level processing power is on some network cards to accelerate the performance of SSL. This is why Network Virtualization is important to consider during performance testing. You won’t exercise TCP in a lab the way it would be in the real world. In our ever increasing mobile gadget world, this is going to be important to address early in performance testing moving forward.
HTTP/2
HTTP 1.1 worked well for the year 2000, but it’s outdated now. The good news is that instead of doing a complete re-write, the new HTTspecifications allow for HTTP 1.1 methods, status codes, and verbiage to remain the same. The actual content of the connection streams contain HTTP 1.1 request headers and the format of the request is the same. With HTTP 1.1, a request would have wait for a free connection to send the request. With HTTP/2, it can be sent out as fast as possible. HTTP/2 also allows the client to set higher priorities on some resources (like the HTML file) and inter-dependencies. Allowing HTTP 1.1 request formats allows for the slow transition over time to HTTP/2 by the industry as a whole.
What makes HTTP/2 awesome for the performance engineer?
- It is a binary protocol instead of a text-based protocol. This makes it faster and more compact when sending across the network. It’s also more efficient to parse through from a machine perspective.
- One connection per server. One connection that goes as fast as possible. By design, there is no performance benefit to use more than one connection any more. HTTP/2 deals with head-of-line blocking issue by allowing multiple request and response messages to occur at the same time, even mixing parts of one with another. This is called Multiplexing.

- HTTP/2 does this using frames. Steve Gibson goes into great detail about frame header size and contents on his podcast, so I won’t repeat it. Here’s my summary: Frames allow a single stream to operate as if it were multiple connections. A 32-bit stream ID defines what frame it is the next one of. Frame sizes up to 16k are allowed by default. Bigger ones are possible if the client gets permission from the server. TCP is still responsible for moving the packets around. HTTP/2 still relies on TCP to guarantee packets won’t get dropped and will be reordered properly. Since HTTP/2 is seen as a single stream, the connection speed is optimized once by TCP slow start. One connection optimized for speed means the server will keep the connection as busy as possible. The server will not have to wait for another request before it does something else. It means the way data is able to move from the server to the client will be faster. I can already hear the sound of many performance testers dancing and singing like the victory celebration at the end of Return of the Jedi.
- Server Push. The latest CPUs utilize speculative processing. Put simply, if the CPU is so fast that it has reached a fork in the road, instead of waiting on the next instruction for guidance, it takes both paths. Once it receives the actual instruction, it disregards the one it didn’t need. Similarly, HTTP/2 Server Push allows a server to send resources to the client that it thinks the browser will eventually need and puts it into its cache. It already has the HTML page with all of the resources defined in it. Instead of waiting on the request for an image, it can go ahead and send resources to the local cache of the browser.
- Security and Good Performance. I’m not going to dive into the security aspects of HTTP/2, but I did want to mention that there no longer has to be a compromise to get security and good performance. The same single connection we’ve been discussing allows for a TLS secure tunnel to be opened as well, allowing HTTP/2 support acknowledgement to happen during the first security handshake. TLS and HTTP/2 acknowledgement with no wasted round trips. Encrypted traffic should be faster on HTTP/2 than unencrypted traffic on HTTP 1.1. No one is going to complain about that.
Product Support
Which products support HTTP/2? LoadRunner 12 currently supports SPDY. I have also read that Neoload supports SPDY. Obviously, this is going to have to be updated for the changes made between SPDY and HTTP/2. (UPDATE 08/15/2016 – LoadRunner 12.53 officially supports HTTP/2 and the latest version of NeoLoad does as well). If you know of others, I’d like to find out. I’m wondering how load testing tool vendors will be able to mimic the behavior of Server Push and deal with Multiplexing.
HTTPWatch has already done some preliminary testing and found an initial 20% or more improvement initially, with Google claiming more than 30% or more on their own applications.
Now that the HTTP/2 spec is pretty much done, it’s ready for developers to start using it and developing support at the client and server level. Code can be developed to utilize a connection optimally and efficiently. As this happens, we may see additional performance improvements over time as HTTP/2 becomes fully adopted. The next few years will be an exciting time to be a performance engineer, as we begin to test HTTP/2 native applications and push the boundaries even farther.
I’m excited about it. How about you? Let me know what you think about HTTP/2. If your company is performance testing a HTTP/2 initiative and need help, contact me.
REFERENCE LINKS:
- https://github.com/http2
- https://http2.github.io/
- https://lists.w3.org/Archives/Public/ietf-http-wg/2015JanMar/0478.html
- http://twit.tv/show/security-now/495
- http://www.engadget.com/2015/02/24/what-you-need-to-know-about-http-2/
- http://thenextweb.com/insider/2015/02/18/http2-first-major-update-http-sixteen-years-finalized/
- http://venturebeat.com/2015/02/24/firefox-36-arrives-with-full-http2-support-and-a-new-design-for-android-tablets/
- http://venturebeat.com/2015/02/18/mozilla-outlines-firefox-roadmap-for-http2/
- http://arstechnica.com/information-technology/2015/02/http2-finished-coming-to-browsers-within-weeks/
- http://www.engadget.com/2015/02/24/what-you-need-to-know-about-http-2/
- https://www.mnot.net/blog/2015/02/18/http2
- http://www.zdnet.com/article/how-http2-will-speed-up-your-web-browsing/
- http://www.theverge.com/2015/2/18/8059951/http-2-faster-basic-web-protocols
- http://www.theverge.com/2012/1/25/2731712/google-spdy-tcp-proposals-faster-internet
- http://http2.github.io/faq/#why-is-http2-multiplexed
- http://daniel.haxx.se/blog/2015/02/01/http2-right-now/
- https://insouciant.org/tech/http-slash-2-considerations-and-tradeoffs/
- “Multiplexing diagram” by The Anome – Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons



